There is still a lot of debate about Data Access Layer design in software development, and about layered architecture in general: what to do, and how to accomplish it.
This is a very broad topic and I have been struggling with it for some time; there are not only different requirements for different situations, but there are individual preferences for particular styles and there are additional requirements forced upon coders by what the software out there is capable of doing.
In these posts, I’m going to try to make some really in-depth sense of the major issues to do with data binding in .NET. The discussion and even the details of the principles involved, however, will be applicable to any language or platform capable of implementing the kind of things we’re talking about, and I’m pretty sure will be a good match for Java at least (since that’s what .NET was ripped off from … oops … don’t mention the war ….).
I develop winforms and web applications, with occasional mobile device work as well, and I’m looking for a robust, flexible layering model I can use to enable re-use of code and classes thoughout any kind of application I choose to develop. While the web paradigm has quite different demands of the presentation side of the application from the others, I can’t see any reason why a well architected application back end wouldn’t be optimal for all purposes.
Layered Design
Layered application design has been around for a long time. In principle, I don’t think anybody debates that it’s a good thing. It’s the implementation which is fiercely contested.
So let’s go back the the principles of layered architecture. If you haven’t come across layered or tiered architecture before, have a look on wikipedia here. A good article on the Model-View-Controller pattern, probably the most prevalent layering pattern in common use at present, have a look here.
I’m not going to worry too much about the details of the different competing patterns, because I want to accomodate them all – and their similarities are generally much greater than their differences.
I’m not going to worry too much about the details of the different competing patterns, because I want to accomodate them all – and their similarities are generally much greater than their differences.
The idea is that layered architecture is good because it allows functionality to be broken into very discrete and controlled units.
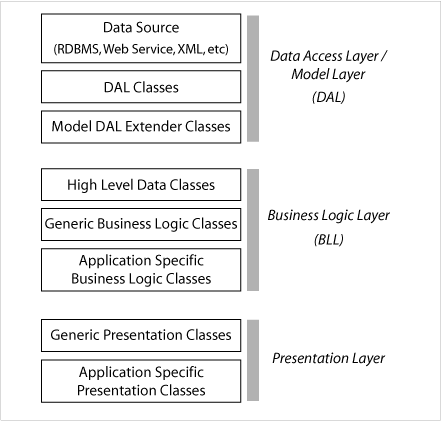
The bottom ‘Data Access Layer’ or DAL is generally based on database tables, but could be XML, data returned by web services or any other data source. In a layered architecture, this information is ‘wrapped’ in a series of objects which generally mirror the granularity of the data, for example there is usually one object per database table, with a data property for each column.
The DAL certainly fits into the ‘Model’ grouping of the MVC pattern. It can be debated that the ‘model’ grouping should also contain extensions to the basic DAL necessary to implement higher functions such as status transitions of the data objects in order to keep basic data model integrity during such transitions (eg. validation of critical data elements and relationships). This should not be business logic as such, but rather the low-level logic required for very basic interpretation and manipulation of the data by any and all calling applications – it’s the protection that the DAL needs to make sure that outside manipulation doesn’t ‘break’ its most basic functions.
I would put these extension classes in a separate group to the basic DAL classes (but it doesn’t matter overly), and they would then complete the Model grouping of the MVC pattern.
Because the basic DAL classes do tend to mirror the underlying datasource exactly, it makes sense to have an autogeneration tool to create these classes, and there are many tools out there which do just this.
The DAL certainly fits into the ‘Model’ grouping of the MVC pattern. It can be debated that the ‘model’ grouping should also contain extensions to the basic DAL necessary to implement higher functions such as status transitions of the data objects in order to keep basic data model integrity during such transitions (eg. validation of critical data elements and relationships). This should not be business logic as such, but rather the low-level logic required for very basic interpretation and manipulation of the data by any and all calling applications – it’s the protection that the DAL needs to make sure that outside manipulation doesn’t ‘break’ its most basic functions.
I would put these extension classes in a separate group to the basic DAL classes (but it doesn’t matter overly), and they would then complete the Model grouping of the MVC pattern.
Because the basic DAL classes do tend to mirror the underlying datasource exactly, it makes sense to have an autogeneration tool to create these classes, and there are many tools out there which do just this.
The primary advantage of complete encapsulation in a data layer is that the back end storage methods can change without affecting the rest of the application at all. All SQL and back-end-specific information is contained within the DAL, so in theory we could decide to swap RDBMS (Relational Database Management System), to change to or incorporate data obtained through web services, and many other options, without the rest of the application knowing or caring.
The classic case is in a large corporate environment where where may be several different legacy systems patched together and in the process of migration, or when in today’s takeover-ridden world, suddenly the corporation buys another company and has to integrate a separate set of data from a different RDBMS into the application.
The classic case is in a large corporate environment where where may be several different legacy systems patched together and in the process of migration, or when in today’s takeover-ridden world, suddenly the corporation buys another company and has to integrate a separate set of data from a different RDBMS into the application.
The middle layer is the ‘Application Layer’ or ‘Business Logic Layer’. I’m going to refer to it as a Business Logic Layer (BLL) for the rest of this discussion. This is the ‘Controller’ grouping in the MVC pattern.
The idea is that the BLL performs all the smarts of the application. It responds to user events, determines what to do and how to do it. It decides what data to read from and write to the DAL and oversees the CRUD (Create-Read-Update-Delete) process, manipulating the DAL as needed.
The idea is that the BLL performs all the smarts of the application. It responds to user events, determines what to do and how to do it. It decides what data to read from and write to the DAL and oversees the CRUD (Create-Read-Update-Delete) process, manipulating the DAL as needed.
The top ‘Presentation Layer’, or the ‘View’ grouping in MVC parlance, is concerned with presentation of information to the user in the form of application screens or web pages, and the gathering of user responses.
‘Views’ are essentially groupings of data similar to the View or Query concept in a database system. Views or collections of views are presented to the user in order (together with fixed structure and content) to make up a screen or page.
In the MVC pattern, there is provision for the model to update the view if underlying data changes asynchronously (eg. changed by another user), but this would presumably be via the management of the BLL.
‘Views’ are essentially groupings of data similar to the View or Query concept in a database system. Views or collections of views are presented to the user in order (together with fixed structure and content) to make up a screen or page.
In the MVC pattern, there is provision for the model to update the view if underlying data changes asynchronously (eg. changed by another user), but this would presumably be via the management of the BLL.
The key issue in working out the division of logic between the BLL and Presentation Layer is to consider how the information would be presented in several different front end media, eg. WinForms, Web Page, PDA page.
Much tightly-integrated information can be displayed on a WinForm, and often a single WinForm might have to be broken down into several web pages or PDA screens to achieve the same functionality.
Does the logic facilitate this ? Does the screen logic concern itself only with the demands of creating the display page and interpreting the response ? Does the BLL logic work at a low enough level of granularity that three quite different screen or page layouts could utilise it without modification ?
If the approporiate division of labour between these top two layers is acheived, then the great advantage is that front end presentation layers for different target technologies can be swapped in and out without major recoding.
Much tightly-integrated information can be displayed on a WinForm, and often a single WinForm might have to be broken down into several web pages or PDA screens to achieve the same functionality.
Does the logic facilitate this ? Does the screen logic concern itself only with the demands of creating the display page and interpreting the response ? Does the BLL logic work at a low enough level of granularity that three quite different screen or page layouts could utilise it without modification ?
If the approporiate division of labour between these top two layers is acheived, then the great advantage is that front end presentation layers for different target technologies can be swapped in and out without major recoding.
Of course, applications as a whole are generally split into functional subsystems which can be naturally encapsulated, and the layered architecture would be realised within each subsystem.
One other topic worth touching on is the additional programming features that have evolved over the past few years which make it much easier to implement this ideal structure in the OO (object oriented) world.
Partial classes and generics are two programming innovations which have quietly snuck into .NET over the last few years. However it is little features like this which make our lives so much easier when we are trying to develop patterns like the ones we are talking about.
Partial classing allows automatic generation tools to create a set of files containing DAL partial classes. If we want to extend or modify a class, we merely create a second empty partial class file in a separate location, and add our logic in, overriding or extending as necessary. When automatic regeneration of the DAL classes occurs, the original files can be blown away and replaced, with the extensions sitting safely somewhere else. Previously, we had to rely on tagging of areas of files as ‘autogen’ or ‘user’, placing any modifications of files in the ‘user’ area – on pain of losing our changes otherwise.
Generics has allowed a lot more safety surrounding the use of polymorphism. We can pass data around to re-usable classes of code while maintaining a type-safely we could only dream of previously.
Partial classes and generics are two programming innovations which have quietly snuck into .NET over the last few years. However it is little features like this which make our lives so much easier when we are trying to develop patterns like the ones we are talking about.
Partial classing allows automatic generation tools to create a set of files containing DAL partial classes. If we want to extend or modify a class, we merely create a second empty partial class file in a separate location, and add our logic in, overriding or extending as necessary. When automatic regeneration of the DAL classes occurs, the original files can be blown away and replaced, with the extensions sitting safely somewhere else. Previously, we had to rely on tagging of areas of files as ‘autogen’ or ‘user’, placing any modifications of files in the ‘user’ area – on pain of losing our changes otherwise.
Generics has allowed a lot more safety surrounding the use of polymorphism. We can pass data around to re-usable classes of code while maintaining a type-safely we could only dream of previously.
Nullable Types
interfaces
In many ways, layered architecture is the natural result of the OOP principles of encapsulation and re-use.
And herein lies one of its primary other advantages – the ability to break down a problem into small, well-defined chunks with specifically written unit tests, and give them to individual members of a large development team.
Crucially, it provides a structure for developers of varying abilities and experience to contribute to a shared effort by ensuring that their component works exactly as specified.
And herein lies one of its primary other advantages – the ability to break down a problem into small, well-defined chunks with specifically written unit tests, and give them to individual members of a large development team.
Crucially, it provides a structure for developers of varying abilities and experience to contribute to a shared effort by ensuring that their component works exactly as specified.
No discussion of layering would be complete without mentioning the shortcomings of the layered approach. We have already mentioned how it is ideally suited to the fragmented realities of large corporate infrastructures and development teams. Exactly this advantage may make it unsuitable for small to medium sites and single-person developer teams.
Indeed, if one takes a look at all of the .NET databinding controls, they are tilted very heavily towards direct SQL access to a database by the front end pages of an application, which is diametrically opposed to the layered philosophy. The suitability of the .NET controls for Object based data binding is very basic at best, and just might not cut the mustard when it comes to refining our layered structure (we’ll see soon …).
While many small to medium size developers would like to design according to the layered approach, in order to ‘future-proof’ the design against future changes, it’s quite common that the additional layering adds up to nothing but a substantial extra amount of short term work for dubious gain. Suppose things don’t change, or the application becomes superseded before it is obsolete.
It is my strong belief that many aspects of the layered approach pay off only as the compexity of the application or its supporting hardware increases. I also believe that the quite different approaches by the large and small developer camps have lead to a glossing over of the key issues in design of the varous layers.
Indeed, if one takes a look at all of the .NET databinding controls, they are tilted very heavily towards direct SQL access to a database by the front end pages of an application, which is diametrically opposed to the layered philosophy. The suitability of the .NET controls for Object based data binding is very basic at best, and just might not cut the mustard when it comes to refining our layered structure (we’ll see soon …).
While many small to medium size developers would like to design according to the layered approach, in order to ‘future-proof’ the design against future changes, it’s quite common that the additional layering adds up to nothing but a substantial extra amount of short term work for dubious gain. Suppose things don’t change, or the application becomes superseded before it is obsolete.
It is my strong belief that many aspects of the layered approach pay off only as the compexity of the application or its supporting hardware increases. I also believe that the quite different approaches by the large and small developer camps have lead to a glossing over of the key issues in design of the varous layers.
Another major point of contention with layering results from the convenience of SQL. There is one thing that SQL does very, very well that OOP can’t come anywhere near. And that is aggregation of data. Using a very clear, straightforward, english-like syntax, an experienced SQL designer can link together ten or twenty tables, and pull out the required aggregated data in an astoundingly short period of time. At the same, kiss goodbye to encapsulation and ‘smart objects’ – SQL tables and columns are just like collections of objects and properties, stored on disk and without any code. There’s nothing like extensive use of SQL throughout an application to get OOP and layering fanatics frothing at the mouth.
The irony is that there’s nothing intrinsically wrong with either approach, they both have great advantages not shared by the other. But they’re so damn incompatible. One thrives on easy connection and merging of data, the other on strict separation and control.
The OOP crew are well aware of this, and this is where things like Linq come into the equation. These are really an attempt to provide the same easy linking and aggregation as SQL, but on a fully OO foundation, and (God bless them)trying to present it in a semi English understandable format as well !
Being a bit of an SQL guru and addict myself, I am watching from the sidelines with some degree of scepticism at the moment, but things are morphing and changing so quickly that I can’t help but be impressed.
The irony is that there’s nothing intrinsically wrong with either approach, they both have great advantages not shared by the other. But they’re so damn incompatible. One thrives on easy connection and merging of data, the other on strict separation and control.
The OOP crew are well aware of this, and this is where things like Linq come into the equation. These are really an attempt to provide the same easy linking and aggregation as SQL, but on a fully OO foundation, and (God bless them)trying to present it in a semi English understandable format as well !
Being a bit of an SQL guru and addict myself, I am watching from the sidelines with some degree of scepticism at the moment, but things are morphing and changing so quickly that I can’t help but be impressed.
Here is a diagram of a layered system showing the rough division of class functionality, keeping in mind that we’ll probably have a library of generic classes we like to use for our projects, as well as the project-specific classes.
Strong Versus Weakly Typed Layering Objects
This issue is at the root of much of the debate in layered design. In the Wikipedia article for Strongly Typed Programming Language Benjamin Pierce is quoted as saying ‘The usage of these terms [ie. strongly and weakly typed] is so various as to render them almost useless’, so I’ll be quite specific about what I mean when I use these terms.
Take the example of a DAL object corresponding to a single database table. The object (say Product) must represent the columns of the Product table (say ProductID, ProductName, etc.) somehow.
Where the columns are exposed as untyped (ie. object type, a ‘variant’ in the old VB6 terminology) properties, the layering is referred to as weakly typed, and where they are forced to an explicit basic type (eg. int, string, float, etc), the layering is referred to as strongly typed.
I would go so far as to say there are four possible ways of exposing the column data:
Where the columns are exposed as untyped (ie. object type, a ‘variant’ in the old VB6 terminology) properties, the layering is referred to as weakly typed, and where they are forced to an explicit basic type (eg. int, string, float, etc), the layering is referred to as strongly typed.
I would go so far as to say there are four possible ways of exposing the column data:
- The properties may simply be a name-value paired collection of object variables which can store any number of column names and values. A column value might be accessed via a function like
public partial class Product …
public object GetColumnValue(string columnName); called like
ColVal = Product.GetColumnValue(“ProductID”) - Similar to (1), but with an enumerated indexor (allowing use of intellisense), eg.
enum ProductColumnName {ProductID, ProductName, …}; public object GetColumnValue(ProductColumnName columnName);
….
ColVal = Product.GetColumnValue(ProductID) - Alternatively, the columns may be represented by individual properties. These may be weakly typed:
public object ProductID;
…
ColVal = Product.ProductID - … or strongly typed:
public int ProductID;
…
ColVal = Product.ProductID
Only (4) is strongly typed.
In fact, (1) or (2) is how most implementations of (3) and (4) actually store the values internally; they simply add a layer of property definitions over the top to ensure that public access is explicitly named and/or strongly typed.
The points of this whole exercise, and the litmus tests, are this:
In fact, (1) or (2) is how most implementations of (3) and (4) actually store the values internally; they simply add a layer of property definitions over the top to ensure that public access is explicitly named and/or strongly typed.
The points of this whole exercise, and the litmus tests, are this:
- if a type change is made in the underlying database and propagated to the objects in bottom level of the DAL, in the strongly typed case (4), any code which uses the property in a type-sensitive way will fail on compile (since the type it is expecting from the property will no longer match the property’s new type). In the weakly typed case, the code will have to cast the ‘object’ type it is given to the type it wants, and the code will not fail until runtime when the program is unable to cast the object to the type it wants.
- if a column name is changed in the underlying database and propagated to the objects in bottom level of the DAL, likewise the explicitly named cases (2), (3), (4) will fail on compile, where the non-explicitly named cases will wait until runtime to throw a ‘column not found’ error.
As a result of these examples, we could add another term: explicitly named, for the layer objects. In the situation where the column values are exposed as individual properties – (3) and (4) – they are definitely explicitly named. Because (2) causes a compile failure (due to the changed enum value), we should really view it as a form of explicit naming as well. This may become useful later on.
Note that we cannot have strong typing without first having explicit naming – otherwise we don’t know ahead of time which column we are going to return the type for. However we can have explicit naming with or without strong typing.
The ability to have code ‘break’ on compile is desirable simply because the development team is notified of the bug very early in the process, and cannot actually compile until the appropriate changes (hopefully not a hack) are propagated through the system. If the error occurs only at runtime, it will only be picked up in testing. If the testing is not thorough, then the bug might get through to the end user before it is picked up.
The typing and naming of properties might seem like academic nit-picking at this stage of the conversation, but rest assured that later on it will become of utmost importance.
Central to the issue is that it is hard to pass explicity named and typed properties around to standardised functions and procedures who need to deal with them, since all references to them need to be hard-coded. The only way to access the properties as a generic list is to use reflection to obtain the property metadata for the object and iterate through the list of properties and values. This is exactly what the .NET databound components do to bind to objects.
And gee, that looks a lot like the weakly typed and named method used to access the columns. Is it worth the extra trouble ? Are we splinting our arms straight here and then designing a really long handled spoon to eat with ?
While explicit naming and strong typing forces people to access the objects in very safe ways, are there much simpler and possibly more powerful ways to allow this access while maintaining the important benefits of strong typing ? Can we combine the two methods somehow ?
This is essentially what this discussion is about.
Central to the issue is that it is hard to pass explicity named and typed properties around to standardised functions and procedures who need to deal with them, since all references to them need to be hard-coded. The only way to access the properties as a generic list is to use reflection to obtain the property metadata for the object and iterate through the list of properties and values. This is exactly what the .NET databound components do to bind to objects.
And gee, that looks a lot like the weakly typed and named method used to access the columns. Is it worth the extra trouble ? Are we splinting our arms straight here and then designing a really long handled spoon to eat with ?
While explicit naming and strong typing forces people to access the objects in very safe ways, are there much simpler and possibly more powerful ways to allow this access while maintaining the important benefits of strong typing ? Can we combine the two methods somehow ?
This is essentially what this discussion is about.
Two Cases
Before proceeding, I want to discuss the nature of the two poles of layering philosophies and find out why they both sit well within their own domains.
The ‘Large Project’ Camp
The large project is often complex in terms of the development team, the platform technologies, and often but not always the application. In a layered architecture, there may be developers or a whole team dedicated to just the presentation layer, or just certain features in the BLL, and often a dedicated DBA administers all changes to the database system(s) and may not be involved in coding at all. Given this scenario, it suits the development style to have the project broken down into many very small pieces. This is the scenario where strong typing has a good mandate.
Planning and analysis is done to some degree. Adding a single column to the application may necessitate committee meetings and approvals, paperwork to track it, followed by small but almost identical code changes by various teams as the new column is explicitly ushered in and out of a whole host of interfaces between objects and finally used by core presentation and business logic. The cost of doing this may run into days of time. However, each team can be assured that they have complete control over what comes in and goes out of their part of the application, and something changed in some other layer cannot easily break their design (if this happens, something will fail to compile and be relatively easily traced back to its source outside).
This methodology locks the development team into a slow, relatively inflexible, and expensive process, but it may well be the best outcome for large corporate scenarios since there is very tight control allowing tasks to manageably be divided into fragments.
Planning and analysis is done to some degree. Adding a single column to the application may necessitate committee meetings and approvals, paperwork to track it, followed by small but almost identical code changes by various teams as the new column is explicitly ushered in and out of a whole host of interfaces between objects and finally used by core presentation and business logic. The cost of doing this may run into days of time. However, each team can be assured that they have complete control over what comes in and goes out of their part of the application, and something changed in some other layer cannot easily break their design (if this happens, something will fail to compile and be relatively easily traced back to its source outside).
This methodology locks the development team into a slow, relatively inflexible, and expensive process, but it may well be the best outcome for large corporate scenarios since there is very tight control allowing tasks to manageably be divided into fragments.
The ‘Small Project’ Camp
The small project is often staffed by a single developer, up to perhaps five developers. There can be a widely varying amount of formal planning and analysis, but the developers usually have a good idea of what they are setting out to build. They may use an agile methodology and consult with their client often (this is not to suggest that agile methodologies are not applicable in large organisations).
These developers often realise that their applications will benefit from a more structured approach, and in particular the unit testing demanded by the agile methodologies. However they often percieve that this locks them into the highly structured OOP approach. When they change or add a column to their database, are they going to want to trawl through several application layers, retyping that same column/property name and type six or seven times ? No way !
In this small team, an individual usually knows enough about the whole application to be able to patch something new in single-handedly if required. And if everyone’s for it, it is nice if the application can be structured so that a new database column just percolates up through the DAL and BLL by itself as part of the existing table data, rather than needing to be explicitly added to anything (this is the point where the OO fanatics choke on their coffee). Welcome to the magic of non-explicit naming and weak typing ! It is entirely possible to define a new database column as long as it is nullable or has a default value (and hence can be left out of an INSERT statement without causing an error), which can trail along with existing table data, but not cause any problems.
These developers often realise that their applications will benefit from a more structured approach, and in particular the unit testing demanded by the agile methodologies. However they often percieve that this locks them into the highly structured OOP approach. When they change or add a column to their database, are they going to want to trawl through several application layers, retyping that same column/property name and type six or seven times ? No way !
In this small team, an individual usually knows enough about the whole application to be able to patch something new in single-handedly if required. And if everyone’s for it, it is nice if the application can be structured so that a new database column just percolates up through the DAL and BLL by itself as part of the existing table data, rather than needing to be explicitly added to anything (this is the point where the OO fanatics choke on their coffee). Welcome to the magic of non-explicit naming and weak typing ! It is entirely possible to define a new database column as long as it is nullable or has a default value (and hence can be left out of an INSERT statement without causing an error), which can trail along with existing table data, but not cause any problems.
No comments:
Post a Comment